
Den exceptionelle genetiske kode

Den genetiske kode er blevet kaldt “det mest imponerende” stykke evidens, der støtter tesen om universel fælles afstamning – at alle nulevende organismer nedstammer fra en fælles stamform (Dobzhansky, 1973, s. 128).
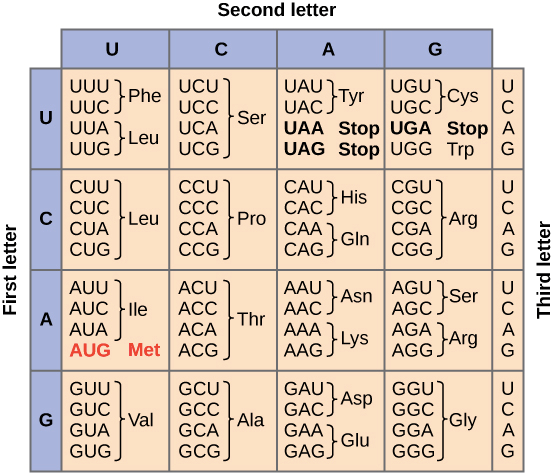
Den genetiske kode er det sæt af regler, alle organismer bruger til at “oversætte” informationen i DNA til proteiner. Tre sammenhængende nukleotider i DNA’et udgør et kodon og koder for en aminosyre eller for “stop” (figur 1). Med få undtagelser bruger alle organismer den samme genetiske kode, og dette tolkes som evidens for, at alle organismer nedstammer fra en fælles stamform, der brugte denne kode.
Biologen Richard Dawkins giver et illustrativt eksempel på argumentet i sin bog, The Blind Watchmaker. Lignende eksempler kan findes i lærebøger og andre tekster, der argumenterer for universel fælles afstamning, men i Dawkins’ eksempel er det meget tydeligt, hvilken rolle argumentets antagelser spiller.
Dawkins starter med at sammenligne den genetiske kode med en ordbog, bestående af 64 DNA-ord på hver tre bogstaver, som har en præcis betydning på protein-sprog (enten en specifik aminosyre eller et punktum). Dette ‘sprog’ har noget meget vigtigt til fælles med andre sprog: “Sproget lader til at være vilkårligt på samme måde, som et menneskeligt sprog er vilkårligt (der er intet iboende i lyden af ordet ‘hus’, for eksempel, der over for en lytter antyder, at der er tale om et sted brugt til beboelse).”
Dawkins fortsætter med at udfolde argumentet for universel fælles afstamning:
“Givet dette er det af stor betydning, at ethvert levende væsen, uanset hvor forskellig fra andre hvad angår ydre fremtoning det måtte være, ‘taler’ næsten nøjagtigt det samme sprog på gen-niveau. Den genetiske kode er universel. Jeg anser dette for at være næsten-endegyldigt bevis for, at alle organismer nedstammer fra en enkelt fælles stamform. Sandsynligheden for, at den samme ordbog af vilkårlige ‘betydninger’ skulle opstå to gange, er næsten utænkelig lille.” (Dawkins, 1987, s. 270; min fremhævelse)
Med andre ord: Givet at den genetiske kode er vilkårlig, udgør den et “næsten-endegyldigt bevis” på universel fælles afstamning. Antagelsen om den genetiske kodes vilkårlighed spiller en central rolle i argumentet, som videnskabsteoretikeren Elliott Sober forklarer:
“Biologer mener, at koden er vilkårlig – der er ingen funktionel grund til, at en given codon skulle kode for én aminosyre i stedet for en anden (Crick 1968). Bemærk hvorledes denne vilkårlighed spiller en afgørende rolle i dette sandsynlighedsargument. Hvis koden er vilkårlig, så støtter det faktum, at den er universel, at alt liv har en fælles oprindelse. Men hvis koden ikke er vilkårlig, ændrer argumentet sig. Hvis den genetiske kode vi observerer var den eneste (eller den mest funktionelle) fysiske mulighed, ville vi muligvis forvente alle levende ting i at bruge den, selv hvis de opstod uafhængigt af hinanden.” (Sober, 2000, s. 42; oprindelig fremhævelse)
Hvis den genetiske kode ikke er vilkårlig, lader den os altså ikke skelne mellem fælles og uafhængig afstamning.
Jeg har i en tidligere artikel argumenteret for, at der er gode designgrunde til at genbruge den genetiske kode, idet genbrug af koden muliggør det fænomen, der kaldes horisontal genoverførsel, og som markant øger mikroorganismers tilpasningsevner (Krauze, 2020). Argumentet i min tidligere artikel fungerer også, hvis den genetiske kode er vilkårlig – muligheden for horisontal genoverførsel kræver kun, at der bruges den samme kode, uanset hvilken.
I denne artikel vil jeg tage skridtet videre og argumentere for, at den genetiske kode ikke er vilkårlig, og at der således er yderligere designgrunde til at genbruge den.
Robusthed over for mutationer
De fleste computere bruger et tastatur med den såkaldte QWERTY-udlægning (opkaldt efter de første seks bogstaver øverst til venstre). Lad os antage, at du er blevet bedt om at designe et tastatur, hvor effekten af slåfejl bliver minimeret, uden at tage højde for ergonomiske hensyn. Du beslutter måske at placere bogstaver, der lyder som hinanden, tæt hinanden – “s” tæt på “z” (som på det nuværende tastatur), “v” tæt på “w”, etc. Zå kan man ztadig læze tekzten hwiz man rammer wed ziden af.
Den genetiske kode lader til at gøre brug af samme logik. Når en celle deler sig, sker der indimellem mutationer eller “slåfejl”, når DNA’et kopieres. Dette kan medføre, at der kodes for en anden aminosyre, der ødelægger funktionen for det protein, det befinder sig.
En aminosyrer er ofte kodet for af kodons, der ligner hinanden – leucin er f.eks. kodet for af CUU, CUC, CUA, and CUG. En mutation i sidste base vil således ikke have nogen betydning for, hvilken aminosyre, der kodes for.
Logikken lader til at gå endnu et niveau ned, hvor aminosyrer med lignende kemiske egenskaber kodes for af lignende kodons. F.eks. kan en mutation i en af leucins kodons resultere i UUU eller UUC, der koder for fenylanin, en aminosyre med lignende kemiske egenskaber. Ligesom vores hypotetiske tastatur er robust over for effekten af slåfejl, lader den genetiske kode til at være robust over for effekten af mutationer.
“Den bedste af alle mulige koder”
I 1998 offentliggjorde et team ledet af Stephen J. Freeland fra Princeton University en analyse, der forsøgte at vise, præcis hvor robust den genetiske kode er. I artiklen, der bærer titlen “The Genetic Code Is One in a Million”, ønskede Freelands team at finde ud af, hvor robust koden er over for en type mutationer, der kaldes substitutioner, hvori ét nukleotid udskiftes med et andet.
Forskerne brugte en computer til at generere en million tilfældige koder, hvor hver aminosyre tilfældigt blev tilknyttet et af de eksisterende kodon-sæt. Forskerne havde udviklet et matematisk mål for robusthed over for substitutionsmutationer, der tog højde for, at nogle typer af substitionsmutationer er mere almindelige end andre – f.eks. er det mere almindeligt, at A bliver udskiftet med G end med C eller T.
Forskerne fandt, at den genetiske kode er exceptionel robust over for effekten af substitutionsmutationer; kun en enkelt af de en million tilfældige koder er mere robuste (Freeland & Hurst, 1998).
I 2000 gentog Freeland-gruppen deres analyse, med én vigtig ændring: De ændrede processen, hvormed de tilfældige koder blev genereret, “for at reflektere plausible biologiske begrænsninger.” Med denne ændring viste den genetiske kode sig at være endnu bedre end først antaget. Den genetiske kode “lader til at befinde sig på eller meget tæt på et globalt optimum for fejlminimering: den bedste af alle mulige koder.” (Freeland et al., 2000)
“Meget mere end blot ‘en ud af en million'”
Substitioner er ikke den eneste slags mutationer. Ved en såkaldt læseramme-mutation (på engelsk frameshift mutation) indsættes eller fjernes en nukleotid, hvilket forstyrrer læserammen for de efterfølgende nukleotider og resulterer i en lang række tilfældige aminosyrer (figur 2). Læseramme-mutationer er især problematiske, hvis de eliminerer et stop-kodon, da dette kan resultere i en ganske lang “nonsenskæde”, der kan forårsage skade i cellen.
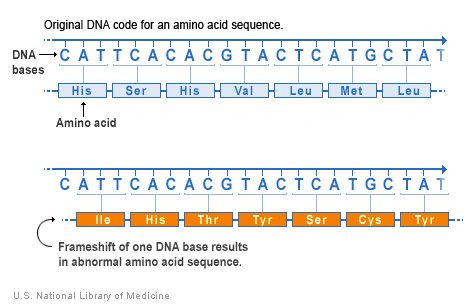
Den genetiske kode er også robust over for læseramme-mutationer. Det skyldes, at den har tre stop-kodons, hvilket kan virke som unødvendigt mange i betragtning af, at der kun er ét start-kodon. Men ved at have tre stop-kodons i stedet for ét stiger sandsynligheden for, at læserammen vil indeholde et stop-kodon, selv efter en læseramme-mutation.
Ydermere er sekvensen for disse stop-kodons lagt i forlængelse af sekvensen for de oftest brugte aminosyrer. Dette øger yderligere sandsynligheden for at finde et stop-kodon efter en læseramme-mutation og gør ifølge en analyse foretaget af to israelske forskere den genetiske kode “næsten optimal” hvad angår robusthed mod effekten af læseramme-mutationer (Itzkovitz & Alon, 2007).
En nyere analyse af Geyer og Mamlouk (2018) kaster mere lys over den exceptionelle genetiske kode. Ved at sammenligne den genetiske kode med en million tilfældige koder, finder de, at målt på robusthed i forhold til enten substitutions- eller læseramme-mutationer, er den genetiske kode “kompetitiv robust”, men “bedre kandidater kan findes”. Men “det bliver betydeligt mere besværligt at finde kandidater, der optimerer alle disse parametre – ligesom SGC [standard genetic code, altså den genetiske kode] gør.” Forskerne konkluderer, at den genetiske kode er robust over for både effekten af subsitutionsmutationer, translationsfejl og læseramme-mutationer, og at den således “lader til at være meget mere end blot ‘en ud af en million’.”
Wichmann og Ardern (2019) har gennemført en lignende analyse af, hvorvidt den genetiske kode er optimeret til flere forskellige parametre på samme tid. Efter at have sammenlignet den genetiske kode med hele 1010, eller ti milliarder tilfældigt genererede koder, konkluderer de, at “optimaliteten af SGC er et robust træk og kan ikke forklares af nogen simpel evolutionær hypotese, der endnu er fremlagt.”
Gode designgrunde til genbrug
Den genetiske kode er langt fra “vilkårlig”. Tværtimod er den exceptionel i dens evne til at beskytte organismen mod effekten af mutationer – en ud af en million eller bedre.
Hvis det første liv var et produkt af intelligent design, ville designerne således have to gode grunde til at genbruge den genetiske kode: Ved at genbruge en vilkårlig genetisk kode muliggøres horisontal genoverførsel (som forklaret i min tidligere artikel) og ved at genbruge den specifikke genetiske kode, som vi observerer i dag, beskyttes organismer i exceptionel grad fra effekten af mutationer.
Fra et designperspektiv er den genetiske kode således ikke et “næsten-endegyldigt bevis” på universel fælles afstamning (Dawkins, 1987), men er også forenelig med separat afstamning.
Referencer
Crick F.H.C., 1968, “The Origin of the Genetic Code”, Journal of Molecular Biology 38(3):367-79. https://doi.org/10.1016/0022-2836(68)90392-6
Dawkins R., 1987, The Blind Watchmaker: Why the Evidence of Evolution Reveals a Universe without Design, W. W. Norton.
Dobzhansky T., 1973, “Nothing in Biology Makes Sense except in the Light of Evolution”, The American Biology Teacher 35(3):125-129. https://doi.org/10.2307/4444260
Freeland S.J. & Hurst L.D., 1998, “The Genetic Code Is One in a Million”, Journal of Molecular Evolution 47(3):238-48. https://doi.org/10.1007/pl00006381
Freeland S.J., Knight R.D, Landweber L.F., & Hurst L.D., 2000, “Early Fixation of an Optimal Genetic Code”, Molecular Biology and Evolution 17(4):511-8. https://doi.org/10.1093/oxfordjournals.molbev.a026331
Geyer R. & Mamlouk A.M., 2018, “On the Efficiency of the Genetic Code after Frameshift Mutations”, PeerJ 6:e4825. https://doi.org/10.7717/peerj.4825
Itzkovitz S. & Alon U., 2007, “The Genetic Code is Nearly Optimal for Allowing Additional Information within Protein-Coding Sequences”, Genome Research 17(4):405-12. https://doi.org/10.1101/gr.5987307
Krauze M., 2020, “Den genetiske kode og universel fælles afstamning”, Intelligent Design DK. https://intelligentdesign.dk/2020/08/08/den-genetiske-kode-og-universel-faelles-afstamning/
Sober E., 2000, Philosophy of Biology, 2nd edition, Westview Press.
Wichmann S. & Ardern Z., 2019, “Optimality in the standard genetic code is robust with respect to comparison code sets”, Biosystems 185:104023. https://doi.org/10.1016/j.biosystems.2019.104023
Kategorier
